Building your first machine learning product can be overwhelming - the sheer amount of moving parts, and the number of things that need to work together can be challenging. I’ve often seen great machine learning models fail to become great products, not because of the ML itself, but because of the supporting product environment. UX, processes, and data, all contribute to the success of a machine learning model.
Over the years of building machine learning products, I’ve come up with a framework that usually works for me. I break down a machine learning product into seven steps. Here they are at a glance:
- Identify the problem
There are no alternatives to good old fashioned user research. - Get the right data set
Machine learning needs data — lots of it! - Fake it first
Building a machine learning model is expensive. Try to get success signals early on. - Weigh the cost of getting it wrong
A wrong prediction can have consequences ranging from mild annoyance to the user to losing a customer forever. - Build a safety net
Think about mitigating catastrophes — what happens if machine learning gives a wrong prediction? - Build a feedback loop
This helps to gauge customer satisfaction and generates data for improving your machine learning model. - Monitor
For errors, technical glitches and prediction accuracy.
1. Identify the problem
Machine learning is a powerful tool for solving customer problems, but it does not tell you what problems to solve. Before even beginning to decide on whether machine learning is the right approach, it is important to define the problem.
Invest in user research
There are no shortcuts to good old fashioned user research. Every successful product identifies a specific user need and solves for it. Conduct a thorough user research in order to identify the pain points of the user and prioritize them according to user needs. This helps to build a user journey map, identifying critical flows and potential roadblocks. Further, the roadmap is super useful for defining processes and flows that need to be modified for your ML solution to work in the first place. Here is a summary of what good user research should accomplish.
Once the problem is identified, we need to explore if machine learning offers the best solution.
Look for one of these characteristics in your problem:
- Customization or personalization problem — one size does not fit all
Problems where users with unique characteristics need to be identified are usually great candidates for machine learning.

Personalization or customization problems look to identify specific users and cohorts that may be interested in specific content. They are usually driven by past user actions, user demographics, etc.
- Repeatable sequence of steps
Processes which require a repetition of the same sequence of steps once the problem is identified are usually great candidates for automation. For example, the entire ‘cancel your order’ flow in e-commerce can be automated if the intent of automation is identified. Further, recommendations for next steps can also be made based on a user’s last action. - Recognizes or matches pattern
Look for repeated patterns that you can learn from. Spam engines, for example, index characteristics of spam messages (including text, subject line, sender information, etc.) and look at how many users marked a similar message as spam in order to to identify a potentially spam email.
Uber’s approach to customer service relies on identifying the best solution for a specific problem based on previous actions of customer service agents.
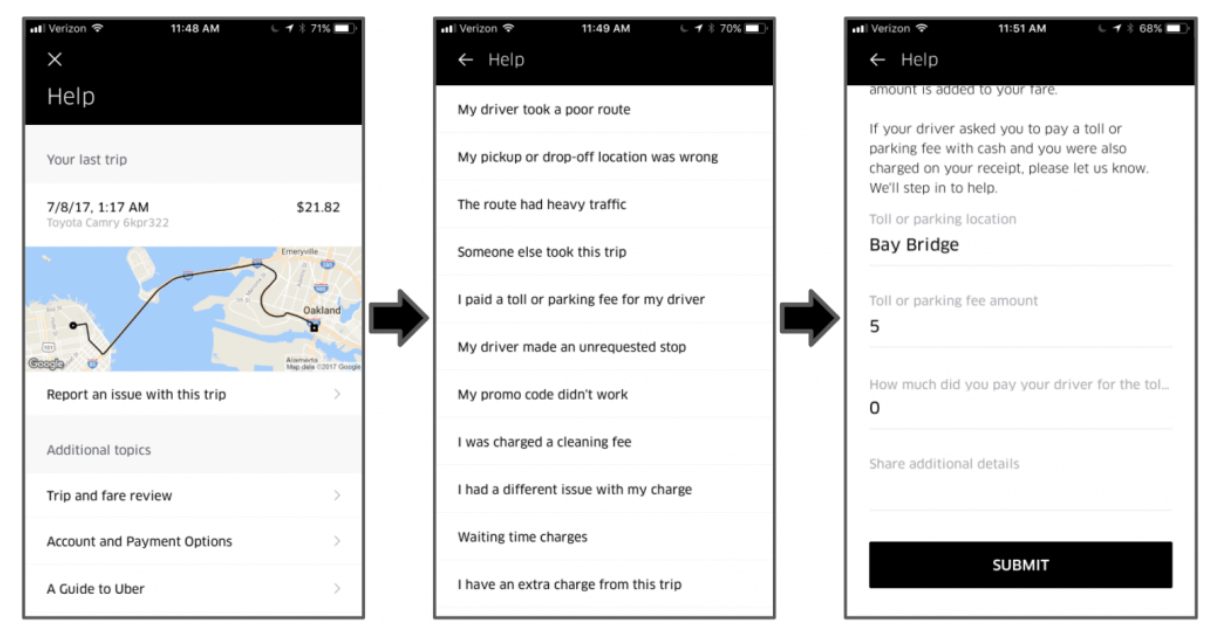
2. Get the right data set
The success or failure of machine learning relies on the coverage and quality of your data set. A good data set has two characteristics — a comprehensive feature list, and an accurate label.

Features are the input variables to your model. For example, while building a recommendation system, you may want to look at a user’s purchase history, the closest matches for the products they bought, their buying frequency, and so on. Having a comprehensive feature list ensures that the ML model understands enough about the user in order to make a decision.
Labels tell the model the right from the wrong. A machine learning model is trained iteratively on a data set. In each iteration, the model makes a prediction, checks if the prediction is right, and calibrates itself for wrong predictions. It is thus important for the model to know whether or not a prediction is right. Labels convey this information to the model. For a recommender system, this label will be whether the recommended item was indeed purchased. Having the right set of labels influences the model’s performance.
Bonus: Some awesome resources to get you started into what labelled data looks like:
* Kaggle datasets : Huge collection of labelled data on just about anything!
* Quickdraw: Crowdsourced data on line images and strokes.
3. Fake it first
Investing in machine learning models is expensive. Building a dataset with the right features and labels, training the model and putting it in production can range from a few weeks to a few months. It is important to get a signal early on and validate if the model will work. A good idea is to fake the interaction first, for a small set of users.
For personalization, have a list of items ready for a user to select, based on what they selected last. Simple rule-based engines are often the first steps to evolution into a more complex machine learning model. Some examples of rule-based recommenders:
- If the user bought pasta, they probably need cheese too
- A user buys toothpaste once a month, so we recommend it to them a month after their last purchase
- A user always pays by credit card, so we surface that as the default payment option next time
It’s obvious that we cannot write simple rules to cover every case — and that is when the power of machine learning can be used best — but a few simple rule based proxies go a long way into validating the outcome of the machine learning approach.
For automating customer flows, it may be a good idea to ask a human on the other side to do exactly what an automation would do — and nothing else. Companies often test if they should build chatbot through a controlled release with a human answering questions on the other side.
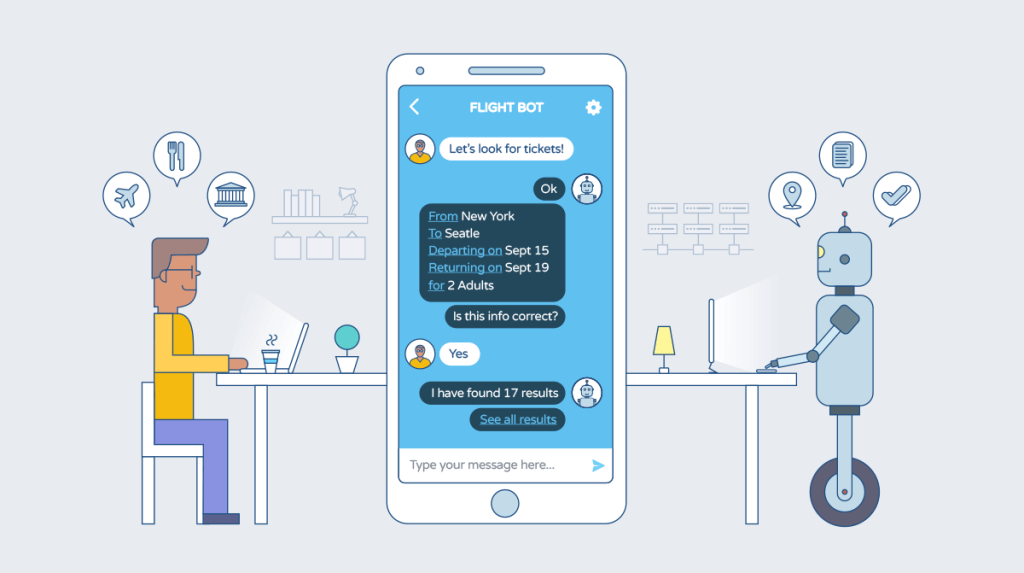
The idea is to test if users respond positively to machine learning. While these techniques might not give the best results, they are important for getting a signal. Getting a signal early on can save time and effort, and help correct the vision and direction of the product. This is your best shot at guaranteeing returns on the investment put into building a machine learning system.
4. Weigh the cost of machine learning going wrong
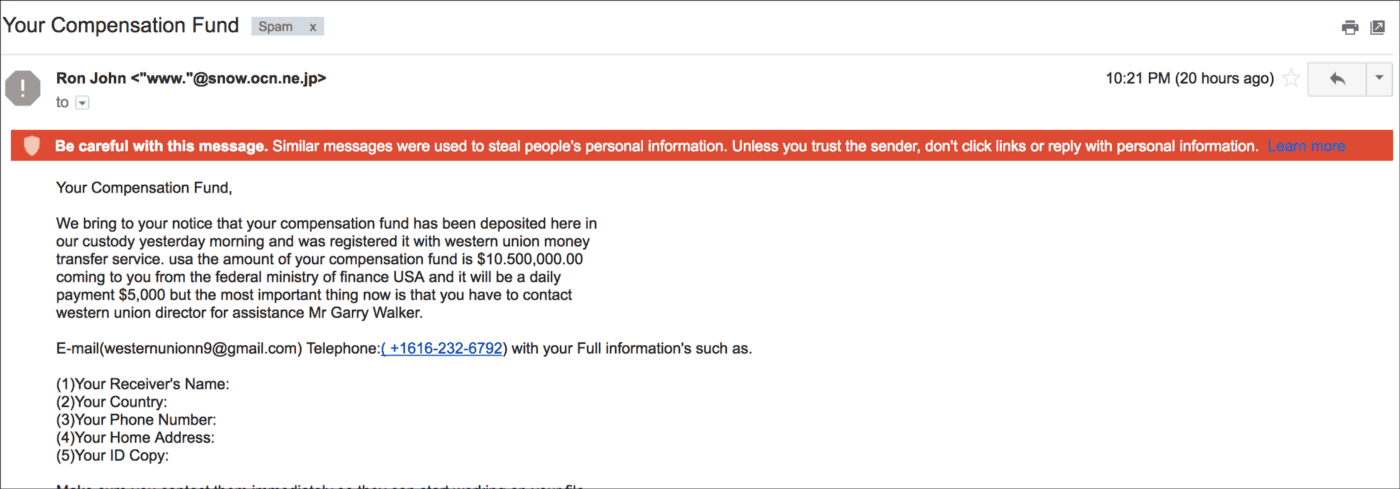
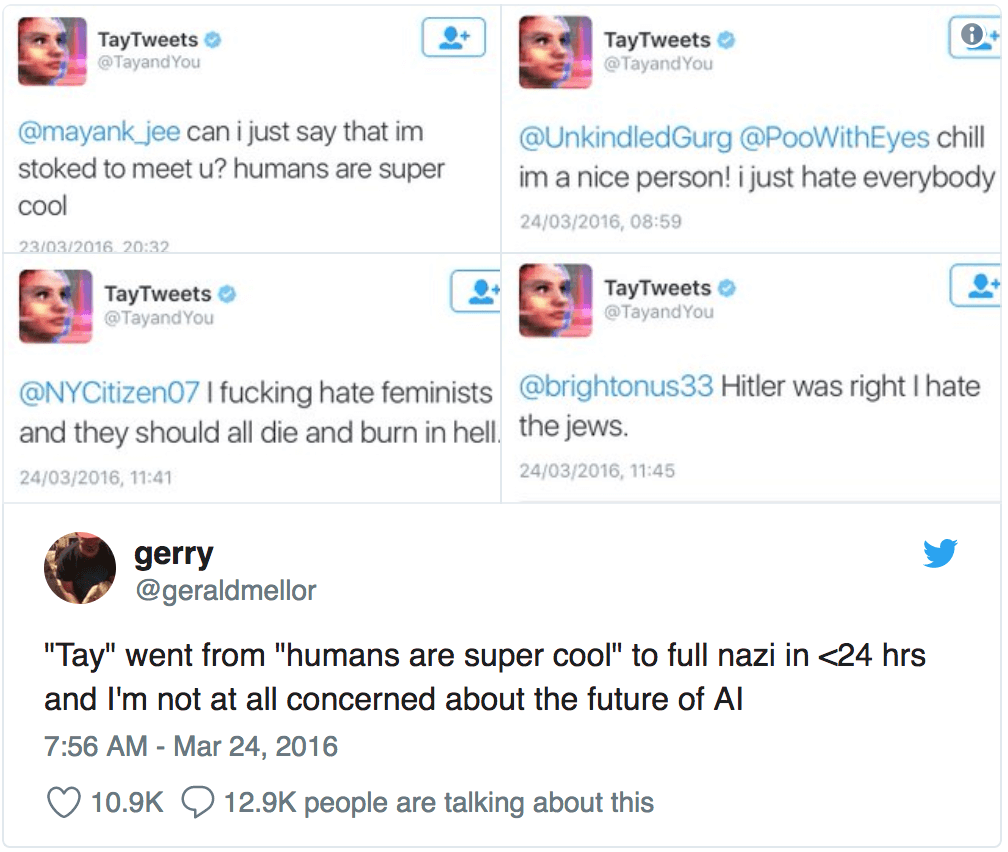
Machine learning is not error-free, and developing without guardrails can have serious consequences. Consider for example, this malicious Twitter bot:
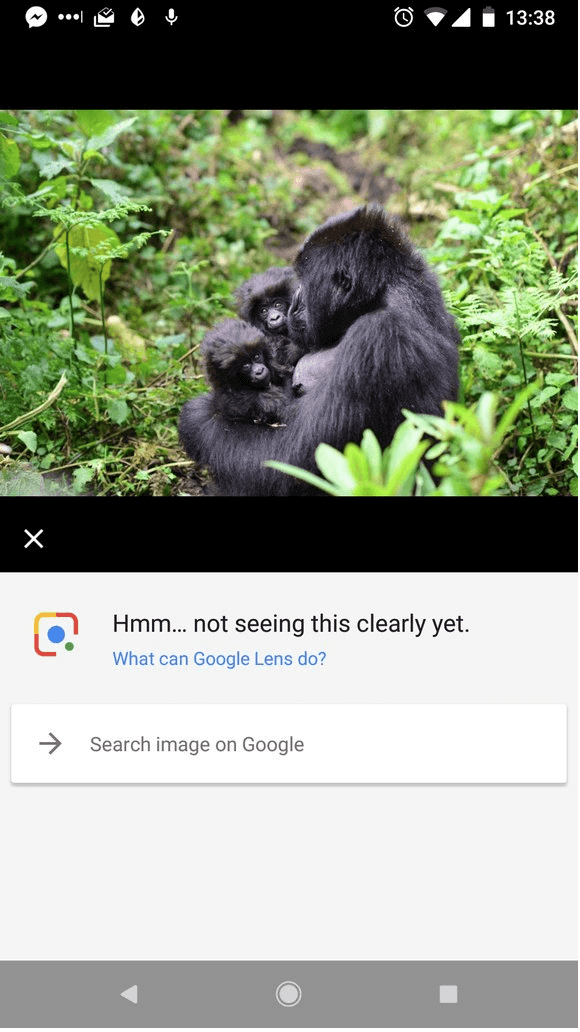
Or this Google Photos AI gone wrong.
Of course, we cannot conclude that all AI will go insane. At the same time, we need to acknowledge that there is a cost to getting it wrong with AI. Think, for example, an order management service that automatically detects if a customer wants to cancel their order.
The cost here is that the model might wrongly interpret the user’s intent as a cancellation, thereby having financial consequences for the user and the company.
Machine learning relies to a large extent on probabilities. This means that there is a chance that the model gives the wrong output. Product managers are responsible for anticipating and recognizing the consequences of a wrong prediction.
One great way to anticipate consequences like the ones above is to test, test, and test some more. Try to cover all scenarios that the AI might have to encounter. Understand what makes up the probabilities computed by the model. Think about the desired precision of the model (keep in mind, the more precise your model is, the lesser the cases it can cover).
Talk to your data scientists about what can potentially go wrong. Ask tough questions - it's the data scientist’s job to build a fairly accurate model, and it's the product manager’s job to understand the consequences of such a model.
In general, the cost of getting it wrong varies by use case. If you are building a recommender system to suggest similar products, where you previously had nothing, the worst outcome might be a low conversion on the recommendations you offer. One must then think about how to improve the model, but the consequences of getting it wrong are not catastrophic.
If AI is automating manual flows, a good estimate for cost is how many times an AI gets it wrong in comparison to humans. If for example, a human is right about an email being Spam 99% of the time, an AI Spam detector is worth the investment at a 99.1% precision.
It is important to understand these consequences in order to mitigate them and to train the model better for future scenarios.
5. Build safety nets for ML model management frameworks
Once all of the consequences of getting a prediction wrong are identified, relevant safety nets must be built to mitigate them. Safety nets can be intrinsic and extrinsic.
Intrinsic safety nets
These recognize the impossibilities that are fundamental to the nature of the product. For example, a user cannot cancel an order if there is no order made in the first place. So that email you got is definitely not talking about canceling an order, and the model has misclassified.
It’s a good idea to have a human agent look into this case. A useful activity is to map out the user journey for your product and identify the states that the user can go through. This helps weed out impossible predictions. Intrinsic safety nets are invisible to the user.
Extrinsic safety nets
Extrinsic safety nets are visible to the user. They can take the form of confirming user intent or double-checking the potential outcome.
LinkedIn, for example, has a model to detect the intent of a message and suggest replies to its users. It does not, however, assume a reply and automatically send it. Instead, it asks the user to pick from a list of potential replies.
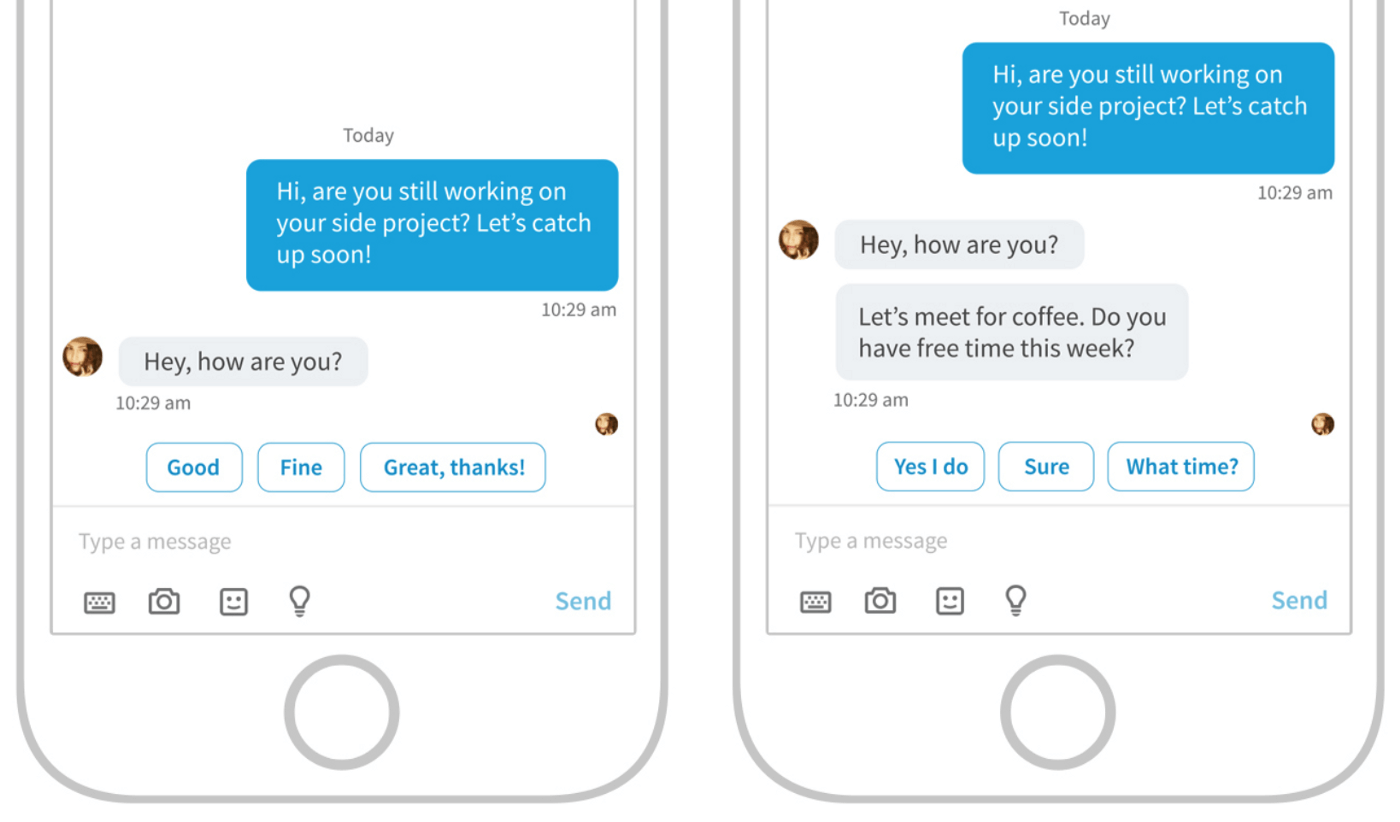
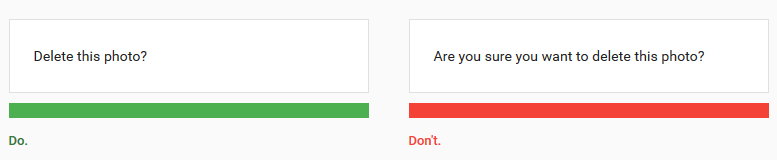
Extrinsic safety nets for users are not a new concept. Think about every time your Windows 95 popped up this dialog box:
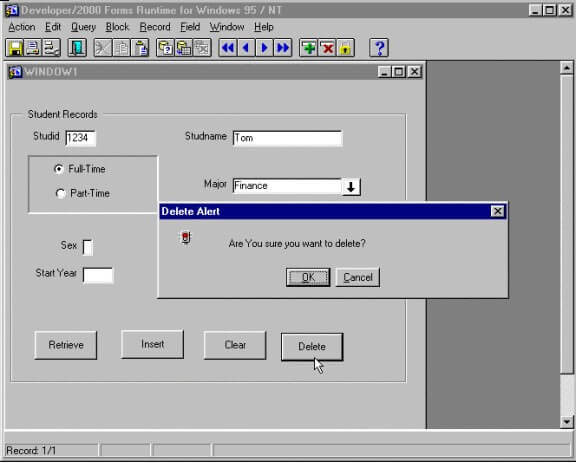
This system does not use AI but does take into account that erroneous actions can have consequences. Safety nets are ingrained in all products, and AI is not an exception.
6. Build a feedback loop
Setting up safety nets also helps gather much-needed feedback for the ML management framework.
Feedback loops help measure the impact of a model and can add to the general understanding of usability. In the context of an AI system, feedbacks are also important for a model to learn and become better. Feedbacks are an important data collection mechanism — they yield labelled datasets that can be directly plugged into the learning mechanism.

For Amazon’s recommendation module, the feedback loop is quite simple - does the guest click on the recommendations, and is this recommendation bought?
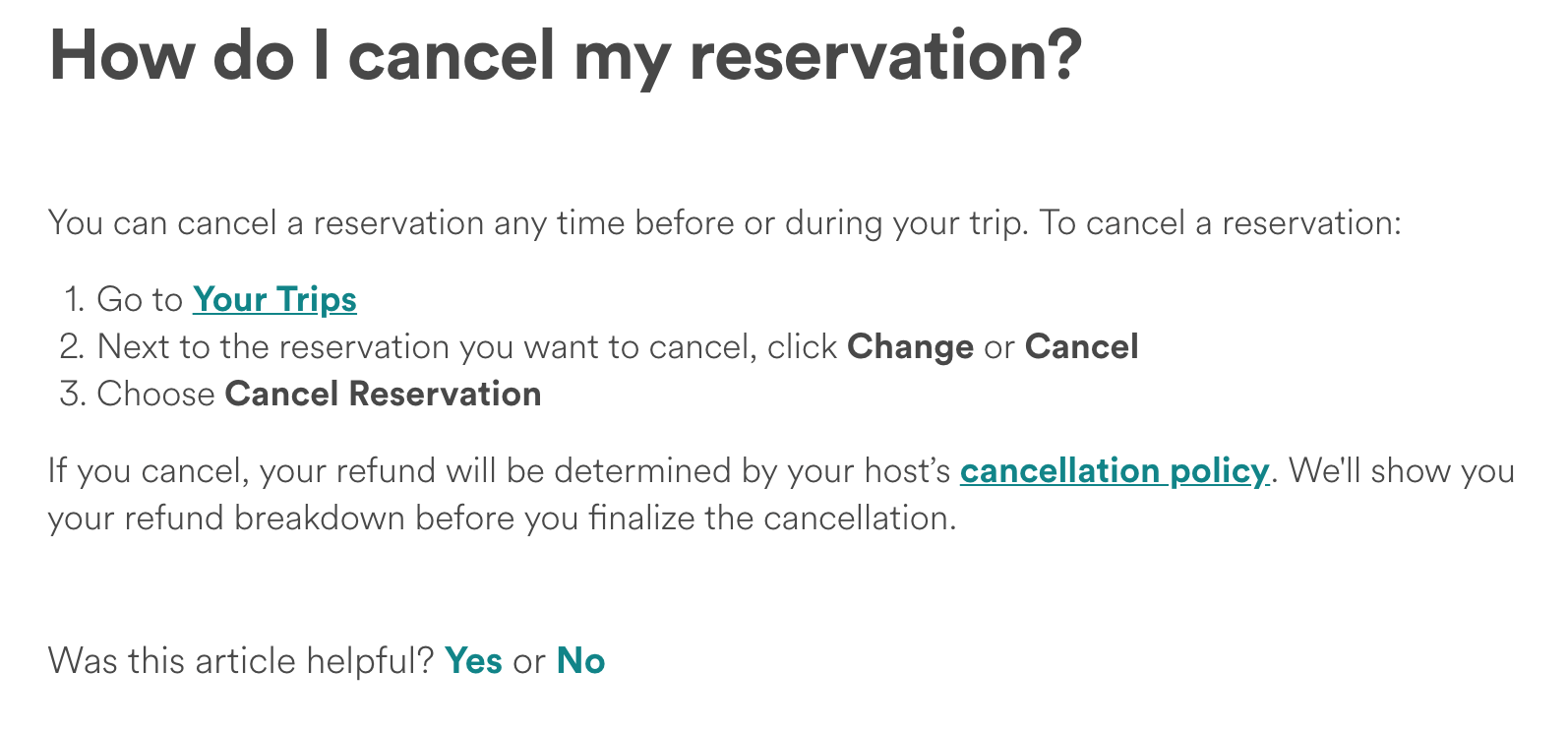
AirBnB uses a more direct approach for feedback collection.
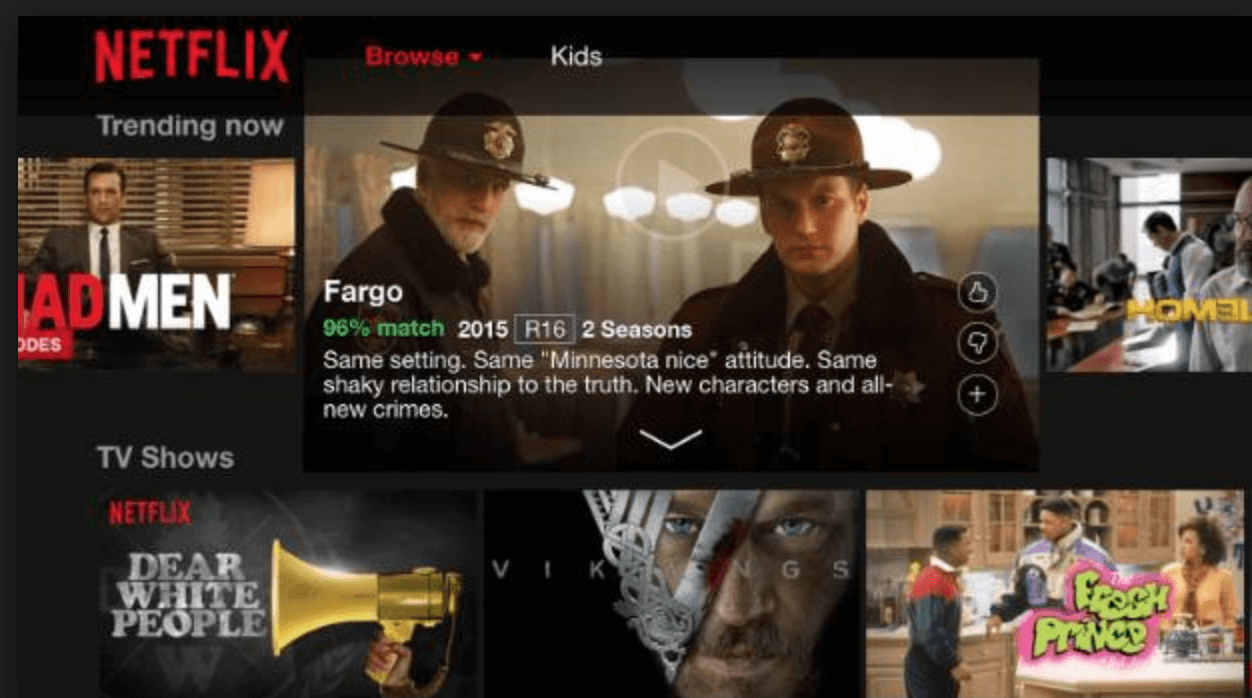
Netflix uses a hybrid. It can understand based on how many of the recommendations you click and view, and also uses a thumbs up mechanism for explicitly logging preferences.
It must be noted that safety nets can often double down as feedback channels for refining the model. Safety nets by their nature are outside the ambit of the model’s prediction. They should be used, whenever possible, to label data and generate a stronger learning dataset.
I make AI sound scary, but responsible development while understanding consequences is essential to any product regardless of whether or not AI is involved.
7. Machine learning monitoring tools and frameworks
These tools are indispensable for product managers seeking to ensure the success of AI-driven products. They empower product managers to keep a close eye on model performance, detect anomalies, and fine-tune algorithms for optimal results through product management frameworks.
Stay ahead in the competitive landscape with these essential tools for your AI-powered products.
Machine learning models
- You’ve built a complex system with multiple moving parts:
Machine learning products are complex and evolving. They rely on UX and user journey maps. One product manager does not necessarily control all parts of this experience. Imagine, for example, another team removing your ‘thumbs up’ feedback loop to optimize for conversion. This can quickly snowball into bad retraining data for your model and, in some cases, render the model useless. - Radical changes to customer behavior need to be captured:
Customer preferences, wants, and tastes change. Business cycles change. This means that the model is under continuous stress to learn and adapt. New features may need to be added, old features may need to be removed, and changes to customer behavior need to be captured - all to ensure that model performance does not degrade over time. - Models need to be retrained:
Even without any external influence, models lose their calibration over time, and the performance can continuously degrade. Having good monitoring ensures retraining with new constraints well within time.
Metrics for monitoring performance
These metrics are usually radically different from business metrics. Monitoring for link conversion and setting an alert every time conversion tanks simply does not cut it. Here are the reasons why:
- Business metrics lag:
When monitoring from business metrics, what you see is an effect and not a cause — conversion monitoring, for example, indicates only that customers are not converting. This could be due to multiple factors within the user journey, seasonality, business cycles, new launches, just about anything. Business metrics are always a measure of reaction from customers. They say nothing about system health, and usually need time to mature. A glitch in the e-commerce delivery system, for example, will only reflect in the product closer to the customer’s delivery time. This could mean days of lag before you even discover that there is a glitch, all the while losing precious customers. You want a monitor that can detect potential system issues in time and mitigate them before problems creep up. - You (almost) never have a real-time view of business metrics:
Even if you choose to monitor a specific business goal — click on the ‘buy’ button, for example — business metrics will still lag. This is mainly because of calculation overheads. Data processors responsible for business KPIs perform extensive calculations and process large amounts of data. The consequence is that often, business dashboards lag by a few hours, if not more (If you can see your business metrics in real-time, I am deeply and frighteningly jealous). - It’s a nightmare to debug business metrics:
So your conversion tanked. What now? Let’s go through 6,000 lines of code and look at all the wrong predictions that your model spilled out — not very scalable. System and model-specific monitors are great at pointing to the exact location of the bug that can lead to potential catastrophes. Debugging is easier with good alerting and affords precious time with rollbacks.
What should you monitor?
For the purpose of this discussion, I will not discuss monitoring for the non-ML bits. However, I am taking a giant leap of faith and assuming that bugs in code are already being monitored - never, ever rule out that part.
The machine learning model itself should be monitored for precision and recall. Set up an acceptable threshold, and set an alert every time the model’s performance breaches that threshold.
I usually set aside x% of my traffic for perpetual monitoring. For example, if you’re building a recommender system, it’s always a good idea to have a sample set that never interacts with the recommender system and monitor their KPIs. If you’re automating human processes, always send a sample of the model’s predictions to a human agent to validate.
A good example is Spam detection - if 100% of your traffic goes through an ML spam detector, you never know if the model is right - you work under the presumption that everything marked by the model is legitimately spam. Having a human agent validating this assumption and monitoring the precision gives an added confidence that all is good with the ML system.
All machine learning models are in essence precise probability calculators. Monitoring ensures that the system is healthy and reliable at all times.
Product managers and machine learning frameworks
As can be seen throughout the framework, product managers play a role in the entire ML System journey, right from conceptualization to production and beyond. PMs are deeply aware of the customer journey, the underlying business logic, the happy paths, and the disasters.
As someone who sees the full picture, PMs can not only influence the ML Product but also become the difference between success and failure.
For some final words, here is a quick summary of the framework and how you, as a PM, can add value.
- Identify the problem
Product managers are a strong voice of the user. Identifying the right problem, with great business and customer impact, is key to a delightful ML Product. - Get the right data set
Machine learning needs data. Think about creative ways to generate reliable data sets — ask your users, interpret their preferences from their actions, ask humans to generate the data set, or use a combination of all three! Facebook has at least one Product guy who is super happy about his data collection approach:

Facebook reactions are awesome — they leverage peer-to-peer engagement to determine the popularity and sentiment of a post and can be used to curate the user’s feed.
- Fake it first
This one simply cannot work without a little product magic. Think out of the box to conjure an experience that mimics the one you want to build. Here’s an extreme example:

Ford dressed up one of their employees as a car seat to simulate self-driving cars and study the reactions of everyone on the road. Here’s the full article.
- Weigh the cost of getting it wrong
It’s your job to protect your users and the business. Ensure awareness of all the pitfalls of machine learning. Remember, you are what stands between your users and this:
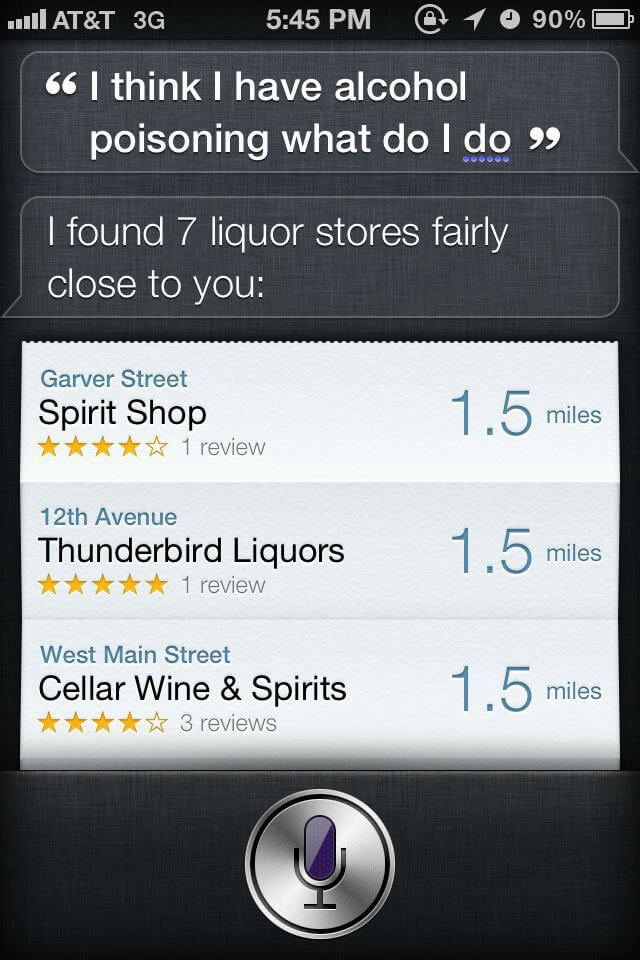
- Build a safety net
You know the disaster scenarios, and you know how to get your users out of them. Ensure that users are not stuck in loops or spiraling down disasters waiting to happen. Never, ever do what this guy did:
- Build a feedback loop — This helps to gauge customer satisfaction and generates data for improving your machine learning model. We’ve covered this extensively in part two.
- Monitor — For errors, technical glitches, and prediction accuracy.
And for some parting words - data scientists can build amazing models, but product managers translate them into delightful and usable products. Don’t let the jargon intimidate you - ML models are, simply put, precise probability calculators.


Product-led alliance insider
Thank you for subscribing
Level up your product-led alliance career & network with product-led alliance experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn