
Let's talk about estimation in product management, it’s a bit of a paradox, isn't it? We all know it is somewhere between art and science.
The Cambridge Dictionary calls it "a guess or calculation about the cost, size, value, etc. of something," which perfectly captures that tension between going with your gut and relying on hard data.
And if you have been in product management for any length of time, you know this tension creates real headaches when you are trying to make business decisions based on these estimates.
Think about how we typically approach estimation: we start with a Simple Wild Approximation Guess (yes, that spells SWAG, and it's about as reliable as it sounds), then work our way to a Rough Order of Magnitude and eventually land on something more refined.
But here’s the thing, we rarely explain exactly how we got there. The process stays fuzzy, and that fuzziness leads to inconsistency and uncertainty, which no modern business can really afford.
I want to explore how AI can shake up this uncertain landscape, giving product managers powerful tools to make better estimates while still keeping that human expertise that makes great product management what it is.
The estimation conundrum
The challenges of estimation in product management have stuck around despite all our technological advances in other areas of business. Let me break down what makes it so tricky:
First, there is the information problem. When you need to make early-stage estimates, you're working with limited information, yet the decisions you make can have huge consequences down the line. It's like trying to choose a college major based on a single class you took in high school.
Then there's the methodology issue. Different teams and individuals use completely different estimation techniques. One team might be using planning poker while another relies on t-shirt sizing, and yet another might be doing something completely different. This creates a patchwork of approaches across organizations, making it hard to compare estimates or establish best practices.
Documentation is another major pain point. How often have you looked at an estimate and wondered, "How on earth did they arrive at this number?" The reasoning behind estimates often vanishes into thin air, which prevents teams from learning and improving over time.
And let’s not forget about the experience factor. The quality of estimates heavily depends on individual experience, which creates a real vulnerability when experienced team members leave. I have seen teams struggle for months after losing a veteran product manager who carried all that estimation wisdom in their head.
So here is the million-dollar question: how can product managers produce reliable estimates with minimal information while building processes that actually get better over time?

The AI estimation partnership
AI offers a promising solution, but probably not in the way you might expect. The real value of AI in estimation isn't about replacing your judgment, it is about enhancing it through a structured partnership. This partnership centers on three key principles:
1. Structured data collection
AI excels at processing structured information. By implementing systems that consistently capture the same categories of information for each estimation exercise, you create the foundation for AI assistance.
This means gathering known constraints and requirements before starting your estimates. It means looking at analogous previous projects that might inform your current work. It means documenting your initial assumptions so they can be tested later and identifying risks and uncertainties that might throw your estimates off.
When you systematically collect this information, AI can analyze patterns across projects that humans might miss because of our cognitive limitations.
For instance, an AI system might notice that projects involving third-party integrations consistently take 25% longer than initially estimated in your organization, a pattern that might be invisible to humans who are focused on individual projects.

2. Feedback integration
The term "artificial intelligence" highlights an important truth; the intelligence being applied is created rather than inherent. This creation process requires deliberate human input.
After a project wraps up, take time to compare initial estimates against actual outcomes. Document the factors that influenced any deviations was it scope creep, technical challenges, or something else entirely?
Explicitly teach your AI system about domain-specific considerations that might not be obvious from the data alone. And continuously refine your input parameters based on results.
This continuous feedback loop ensures that your AI system evolves in alignment with organizational realities rather than abstract theoretical models. I have seen teams transform their estimation accuracy by simply committing to this feedback process for six months.

3. Iterative improvement
Perhaps the most significant advantage AI brings to estimation is its capacity for consistent learning. Unlike human teams that may experience knowledge loss through attrition, AI systems maintain and build upon their understanding over time.
This creates a virtuous cycle where each estimation exercise improves the AI's predictive capabilities. Improved predictions lead to better business outcomes, which reinforce confidence in the estimation process.
This increased confidence encourages more comprehensive data collection, further enhancing the system's capabilities.
What you are doing is transforming estimation from a necessary but frustrating exercise into a strategic capability that drives competitive advantage. I have watched organizations go from treating estimation as a necessary evil to seeing it as a key differentiator in their ability to deliver predictable value to customers.

Practical implementation
Implementing AI-assisted estimation requires a thoughtful approach that respects both technological capabilities and human expertise. Here is how you might go about it:
Start small: The SWAG enhancement
When I first experimented with AI-assisted estimation, I combined Copilot's AI insights with historical data from past sprints. The result was a hybrid approach that used AI-driven prompts for initial sizing and historical comparisons to ground estimates in reality.
Here's a snapshot of what this looked like in practice:
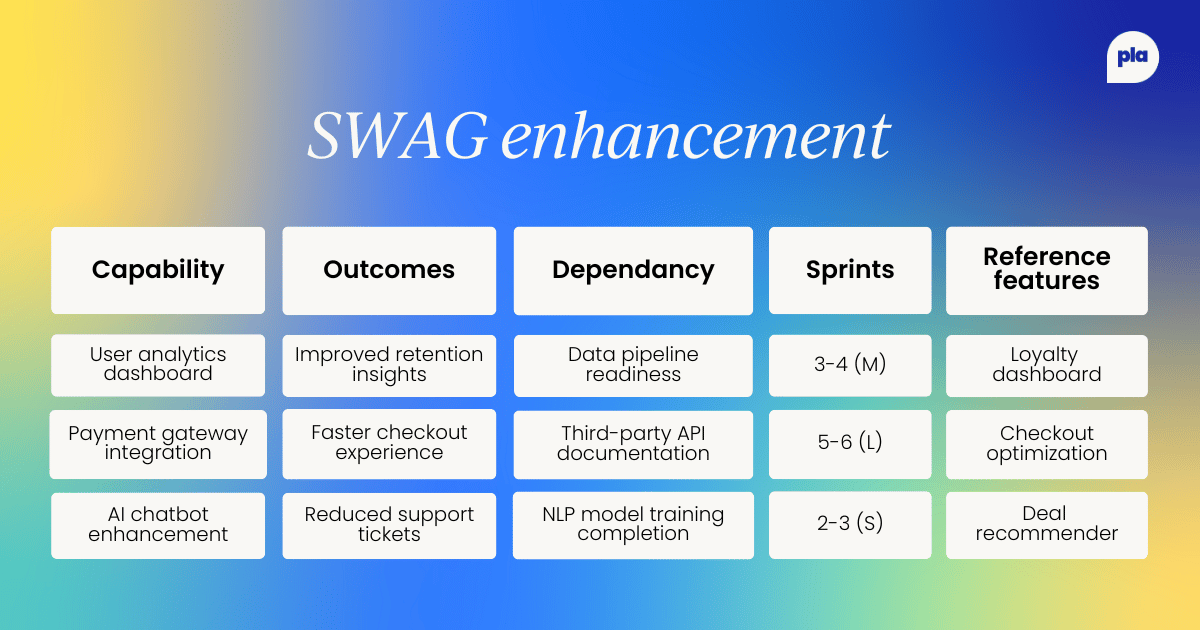
The key insight was that without data, AI estimates weren't particularly useful. The most reliable estimates leaned heavily on similar past features; for example, our previous "Checkout Optimization" work informed our estimates for the Payment Gateway integration.
We also got better at flagging dependencies early; knowing we were waiting on API documentation added a full sprint to our estimate for the Payment Gateway work.
What impressed me most was how our accuracy improved over time. After about 50 iterations, we were hitting an 85-89% accuracy rate on our estimates, which was a game-changer for our planning process.
Lessons learned: Don’t wing it
Through this process, I discovered several important principles for making AI-assisted estimation work, each one learned the hard way through painful project delays and uncomfortable stakeholder conversations.
Validate assumptions
First, always cross-check assumptions. I learned this lesson during a critical e-commerce feature launch when we blindly trusted Copilot's estimate without validating it against our past experience.
The AI suggested X number of sprints without telling the length of the sprint based on general industry patterns, but it missed crucial complexities specific to our legacy payment system.
The result? A project that ran 60% overestimate and a very unhappy stakeholder who had already promised the feature to the franchise.
Now, validation is a non-negotiable step in our process. We always ask, "Does this estimate align with our past experience?" before accepting any AI recommendation.
The consequences of skipping this validation can be severe: missed market opportunities, resource allocation nightmares, and damaged credibility with stakeholders.
One bad estimate can undermine months of trust-building with your executive team. I have seen product managers lose decision-making authority because they couldn't reliably predict when features would be ready.
Track estimated vs actual outcomes
Second, build a repository of your SWAGs and track estimated versus actual outcomes religiously.
This lesson emerged after a painful quarterly planning session where we realized we were making the same estimation mistakes repeatedly. Without historical data, we couldn't demonstrate whether we were improving or just guessing differently each time.
We created a simple spreadsheet that logged every estimate along with the actual time taken and any notable factors that influenced the outcome.
Six months later, during our next major roadmap planning, this repository proved invaluable, we identified that integration features consistently took 40% longer than we estimated, while UI enhancements were typically on target.
This insight alone helped us deliver an entire quarter's roadmap on time for the first time in company history.
Teams that neglect building this repository end up in an endless cycle of estimation amnesia, never learning from past projects, and repeating the same mistakes.
I've watched organizations struggle with chronic delivery issues simply because they never connected their estimation practices to outcomes in a systematic way.
Be aware of AI biases
Finally, be aware of potential bias in your AI system. This lesson hit home during our annual planning when our AI assistant consistently underestimated the complexity of accessibility features.
After investigation, we realized our historical data contained very few accessibility projects, and those we did have were simple implementations. The AI had no frame of reference for complex accessibility work.
AI mirrors your inputs, if you feed it biased or incomplete data, you will get biased and incomplete estimates back. We learned to diversify our reference projects and to be especially careful about excluding outliers that might skew the AI's understanding. We now regularly audit our training data for blind spots and gaps.
Ignoring bias in your AI system doesn't just lead to bad estimates, it can perpetuate organizational blind spots and reinforce existing weaknesses in your development process.
In our case, consistently underestimating accessibility work was actually revealing a deeper organizational issue: we were not prioritizing accessible design properly, which created technical debt and last-minute scrambles to comply with standards.

Develop an estimation knowledge base
As your estimates accumulate, create a searchable repository that pairs initial estimates with actual outcomes, environmental factors, and lessons learned. This knowledge base becomes invaluable both for human reference and as training data for your AI assistant.
In our team, this evolved into a wiki where each major feature had its own page documenting the estimation journey. We included initial assumptions, mid-project adjustments, final outcomes, and a retrospective analysis. This became one of our most referenced resources for new projects and new team members.
Over time, this knowledge base turned into an organizational asset that appreciated in value. The more we used it, the more valuable it became, creating a powerful flywheel effect for our estimation process.

The human element remains essential
While AI brings powerful capabilities to estimation, human judgment remains irreplaceable. The ideal approach combines AI's ability to process vast amounts of historical data and its freedom from cognitive biases with human contextual understanding and strategic insight.
I have found that AI is particularly good at identifying patterns in historical data like noticing that features requiring database schema changes typically take 30% longer than comparable features without such changes.
But humans excel at identifying novel factors not present in historical data, such as recognizing that a new regulatory requirement will impact development in ways the AI couldn't predict.
This partnership creates estimates that are both more accurate and more defensible than either approach could achieve independently.
In our organization, we have developed a rhythm where AI provides the initial estimate based on historical patterns, and then the product and engineering teams review it with an eye toward unique contextual factors that might influence this specific project.
Conclusion
Artificial intelligence represents a transformative opportunity for product management estimation, not by replacing human judgment but by enhancing it.
Through structured data collection, consistent feedback integration, and iterative improvement, product managers can develop estimation capabilities that get better with each application.
The key insight is that AI isn't a magic solution but rather a dedicated assistant that learns exactly what you teach it.
By approaching AI as a collaborative tool rather than an autonomous solution, you can fundamentally transform estimation from an uncertain art into a refined science while preserving the human expertise that defines exceptional product management.
Organizations that embrace this approach gain not only more accurate estimates but also a competitive advantage through improved resource allocation, more reliable roadmaps, and enhanced stakeholder confidence. In the increasingly competitive landscape of product development, these advantages may prove decisive.
I have seen firsthand how teams that adopt this approach move from constant firefighting mode to predictable, confident delivery. The peace of mind that comes from reliable estimation ripples through the entire organization, from engineering to sales to the C-suite.
It’s not just about better numbers, it’s about building trust and creating the foundation for sustainable growth.


Become a PLA Insider
Thank you for subscribing
Get exclusive insights, frameworks, and strategies from product leaders driving real business impact.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn


