












As AI becomes a standard part of more products, I’ve seen a recurring pattern: many of the hardest problems aren’t about building better models. They’re about helping users find the right content, at the right time, in a way that feels genuinely useful and trustworthy.
These challenges (often grouped under “relevance”) show up repeatedly in real product decisions, but they’re not always discussed explicitly in traditional AI PM conversations.
1. Most relevance problems look like small, reasonable tradeoffs
For a long time, traditional product management in AI-driven systems followed a familiar loop: define goals, improve machine learning (ML) models, ship ranking gains, and watch metrics move. In many cases, that approach worked. Until it didn’t.
In several large-scale ML-recommended products I’ve worked on, we reached a point where models were objectively strong. Offline metrics looked healthy. Online experiments showed incremental lifts. And yet, user feedback became increasingly consistent: content discovery became repetitive, recommendations felt slightly off, and people struggled to find content that actually matched what they were looking for.
What made this difficult was that nothing was obviously broken. Engagement didn’t collapse. Dashboards looked fine. But over time, we saw patterns like:
- Users engaging intensely for a short period, then disengaging
- High-quality content performing extremely well once users found it, but rarely being shown
- Content producers creating valuable content that clearly met demand, yet failing to get distribution
After many iterations, we discovered that the issue wasn’t really model quality. It was relevance. More specifically, the system learned to represent content faster than it learned to understand user intent.
2. Over-optimization can lead to models locking in wrong assumptions
When relevance drops, the default reaction is optimization. Tune features. Add signals. Adjust weights. Improve recall. I’ve done this many times, and early in a system’s lifecycle, it works.
At scale, those gains diminish quickly.
Ranking assumes the system already understands users and content reasonably well. In practice, that assumption often breaks down. Users don’t have a single intent. Content doesn’t fit neatly into labels. And engagement signals frequently reflect habit or convenience rather than satisfaction.
I’ve seen systems where ranking precision improved month over month, yet users still described the experience as “not quite right.” When we dug in, the issue wasn’t that content was being scored poorly. It was that the system didn’t understand what the user was trying to accomplish at that moment.
Traditional signals – clicks, dwell time, likes – are useful, but they’re proxies. At scale, they introduce blind spots:
- Users consume content they don’t actually value
- Passive behavior overwhelms explicit feedback
- Minority or long-term interests disappear into averages
- New or niche content struggles to surface
At that point, more optimization doesn’t fix the experience. Better understanding does.
Once we accepted that ranking wasn’t the constraint, the real question became whether the system could understand user context, not just behavior.
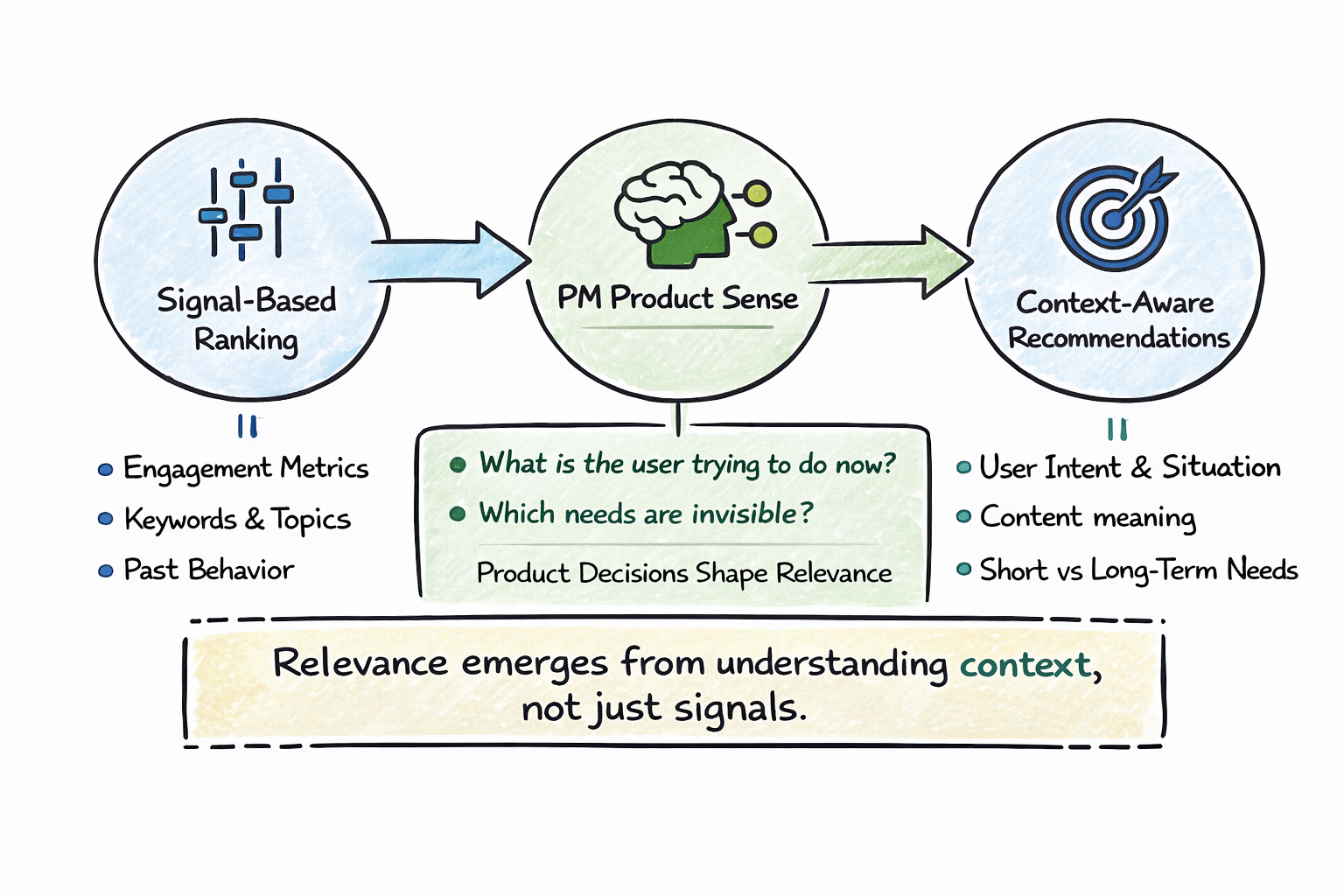
3. Turning signal-based ranking into context-aware recommendations is a product decision
This is where recent advances in large language models (LLMs) start to matter in a practical way.
Instead of only asking, “What did the user click?”, we’ve now started asking:
- What is this content actually about?
- What kind of need does it serve?
- How does it relate to the user’s broader interests or current context?
That shift unlocked new ways to reason about product problems.
On one of the surfaces I worked on, we noticed a recurring pattern – certain posts consistently drove high completion, saves, and follow actions after users saw them, but impressions remained stubbornly low. We initially treated this as a ranking problem and experimented with boosting and feature tuning. The gains were short-lived.
When we stepped back, the issue became clearer. The system understood the topic of the content, but not the situation it was most relevant for. The same content was being evaluated as broadly interesting, when in reality it was highly valuable only in specific contexts: early exploration, problem-solving moments, or after a related interaction.
Once we reframed this as a representation gap rather than a ranking gap, we focused on improving how the system modeled user intent and context. Distribution improved naturally, without ongoing manual intervention.
Relevance improvements often begin with feedback like, “Recommendations don’t get me.” That statement isn’t actionable by itself. The PM’s role is to structure it:
- Is this a topic mismatch?
- A depth or expertise mismatch?
- A timing or context issue?
If a human can articulate why something feels wrong, a system can often be taught to approximate that judgment. LLMs help by making implicit meaning easier for systems to work with, but the leverage still comes from product sense.
4. The product decisions behind relevance
Relevance PMs rarely describe their work as ranking or modeling work. What they’re actually doing is deciding what the system should take seriously and what it should treat as noise.
In practice, relevance work becomes more effective when PMs stop asking how to push metrics and start asking what the system believes about its users. Many relevance failures don’t come from weak models; they come from assumptions that quietly harden over time. Once those assumptions set in, optimization only reinforces them.
I’ve seen this most clearly in new product launches. Early engagement often looks healthy. People explore, click broadly, and interact out of curiosity. But over time, that curiosity fades, and usage starts to thin out. Ranking improvements may move metrics slightly, but they don’t change the trajectory.
The issue usually isn’t exposure or scoring; it’s that early signals were interpreted as durable intent. The system learned too quickly, and too confidently, from behavior that was never meant to be predictive.
What changed outcomes wasn’t another ranking adjustment. It was re-framing the problem around intent. Once we treated early behavior as exploratory rather than declarative, and separated short-term curiosity from sustained interest, the experience began to feel more aligned. Discovery stabilized not because the system was pushed harder, but because it was allowed to be more uncertain.
The same pattern shows up in how teams handle vague feedback. Comments like “recommendations don’t feel useful” are easy to dismiss because they aren’t immediately actionable. But treating them as a single quality issue usually leads nowhere. Progress only came once we forced ourselves to break that discomfort apart, whether the issue was depth, timing, or intent. Each of those failures asks the system to learn something different.
Across these situations, the throughline was consistent. Relevance improved when we stopped treating feedback as something to optimize against, and started treating it as a signal about what the system didn’t yet understand.
This is where product judgment actually shows up. Not in tuning weights or adding signals, but in deciding:
- Which behavior is meaningful versus incidental
- Which feedback should shape learning versus be ignored
- Which assumptions the system is allowed to carry forward
None of this requires writing model code. It requires deciding what the system should care about, what it should remain unsure about, and where learning should slow down instead of accelerate.
This article was originally published on Mind The Product.


Become a PLA Insider
Thank you for subscribing
Get exclusive insights, frameworks, and strategies from product leaders driving real business impact.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn



